AutoWiki-skill
![]()
AutoWiki
Your LLM Compiles a Knowledge Base. You Just Read and Ask.
Implementing Karpathy's LLM Knowledge Base vision — raw sources in, Obsidian wiki out.
By AlphaLab-USTC

English · 中文
The Idea
Good survey papers don’t just list references — they identify milestones, trace how ideas evolved, and organize the field into a coherent structure. AutoWiki does the same thing, automatically.
Drop papers in. The LLM identifies milestone nodes (conceptual breakthroughs), clusters papers around them, builds a hierarchical file tree that mirrors the field’s structure, and writes deep analysis with temporal links between sources. You get a survey-quality knowledge graph maintained in Obsidian — not a folder of disconnected notes.
You drop PDFs LLM compiles You browse in Obsidian
───────────── ────────────────────────── ──────────────────────────────────
raw/new/ → Identify milestones kb/topics/ (milestone nodes)
Cluster papers kb/sources/ (deep analysis pages)
Trace temporal evolution kb/journal/ (cognitive timeline)
Write cross-linked wiki index.md (survey-style tree)
🚀 Quick Start
1. Clone & Install
git clone https://github.com/AlphaLab-USTC/AutoWiki-skill.git
pip install PyMuPDF
2. Add as Skill
In Claude Code or OpenClaw, just ask:
> "Add /absolute/path/to/AutoWiki-skill/skills to my global skillSources"
3. Initialize Your Wiki
cd your-wiki-project
mkdir -p raw/new raw/compiled kb/{sources,topics,journal} output
touch kb/index.md kb/log.md
4. Start Using
Open the project root as an Obsidian vault, then in Claude Code / OpenClaw:
> "Ingest the paper in raw/new/"
> "How does X compare across the Y papers?"
> "Lint the wiki"
Prerequisites: Claude Code or OpenClaw + Obsidian + Python 3.12+
How It Works
raw/new/ ──→ LLM (Claude Code) ──→ kb/ ──→ Obsidian
you drop reads, analyzes, sources/ you browse
PDFs here links, writes topics/
journal/
| Layer | Role | Who owns it |
|---|---|---|
raw/ |
Source archive (PDFs + figures) | You drop files; agent organizes |
kb/ |
Living wiki (markdown + wikilinks) | Agent writes & maintains everything |
Three operations: Ingest (PDF → analysis page), Query (ask questions → synthesize → write back), Lint (25+ auto-checks).
What Makes It Different
| 🧠 Deep Analysis | Not summaries. CRGP factors from the author’s Introduction. Critical analysis with prior/update contrastive structure. Anti-patterns prevent generic filler. |
| 🔗 Temporal Graphs | Every source positioned in the field’s timeline. Evolutionary chains, cross-domain links, temporal tensions — all automatic. |
| 🏠 Self-Healing | Three-tier autonomy: Silent (fix links) → Notify (record insights) → Confirm (restructure). 25+ lint checks. |
| 🎯 Smart Classification | 3-question fitness check before every topic assignment. Auto-scaling: <5 inline, ≥5 split, >8 sub-cluster. |
📂 Showcase: 80-Paper Wiki
We built a real wiki on Agent Self-Evolution — 80 papers, 13 milestones, 2 hours. Here’s what the LLM compiled (compiling 80 papers in Claude Code with Opus 4.6 cost ~150 🔪 of quota):
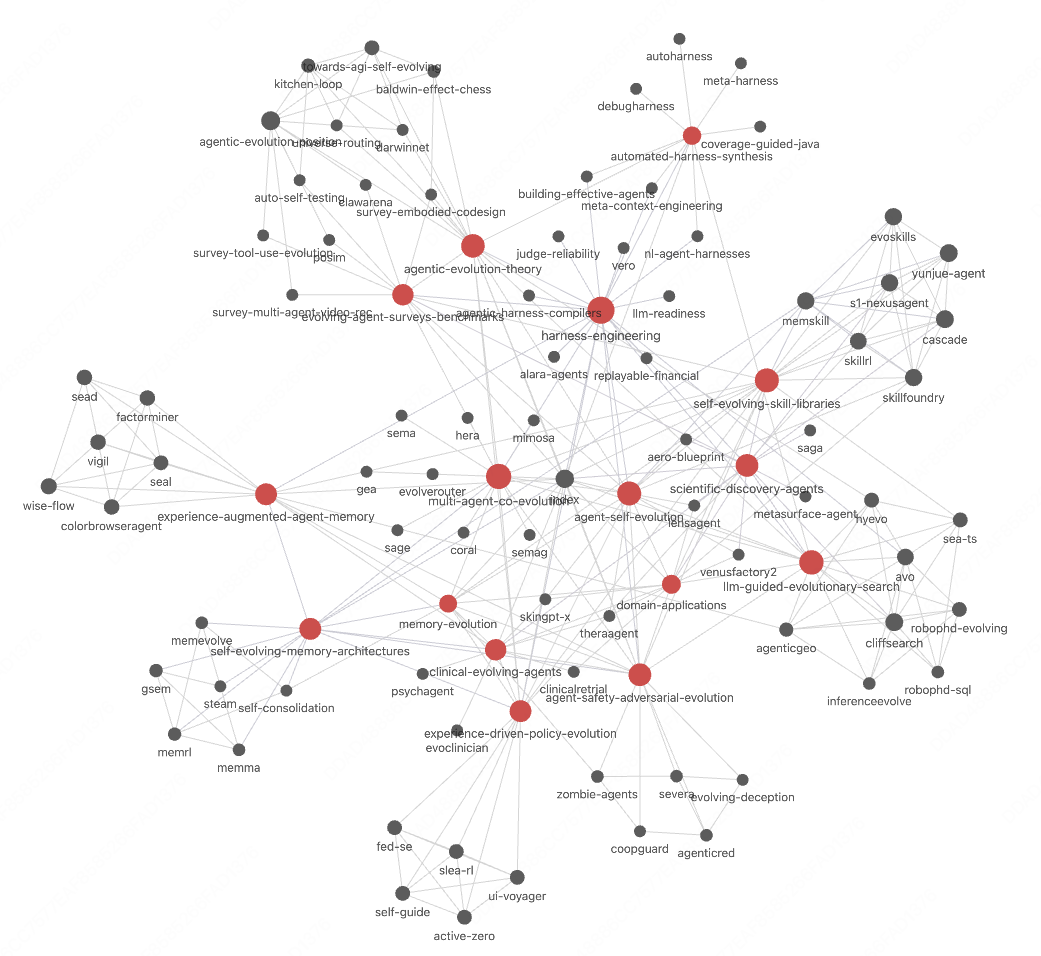
Each node is a source page. Red nodes are milestone topics. Edges are temporal relations (extends, complements, contrasts_with) — all discovered automatically.
Survey-Style Topic Organization
Each topic is a milestone node — like a survey paper, it tells the story of how a research direction evolved.
agent-self-evolution (80 papers, 13 milestones)
├─ Mechanism Layer
│ ├─ self-evolving-skill-libraries (7 papers)
│ ├─ memory-evolution (12 papers, 2 sub-children)
│ ├─ experience-driven-policy-evolution (5)
│ ├─ llm-guided-evolutionary-search (8)
│ └─ multi-agent-co-evolution (8)
├─ Application Layer
│ └─ domain-applications (10 → scientific + clinical)
└─ Cross-Cutting Layer
├─ agentic-evolution-theory (6)
├─ agent-safety-adversarial-evolution (5)
└─ evolving-agent-surveys-benchmarks (6)
What the LLM Compiles
| Output | Example | Live Demo |
|---|---|---|
| Topic — milestone node organizing a research direction | agent-self-evolution (80 papers → 3-layer taxonomy) | ▶ View Topic |
| Source — single paper deep analysis page | MemSkill (Zhang et al., 2026) — learnable memory skills | ▶ View Source |
Topic content preview — agent-self-evolution.md
> **Milestone Definition:** The paradigm of LLM-based agents that autonomously improve their capabilities post-deployment — treating evolution-time compute as a third scaling axis alongside training-time and inference-time compute. **Synthesis** — Three orthogonal layers: - **Mechanism** (what/how evolves): skill repertoire, memory system, decision policy, programs/algorithms, agent populations - **Application** (where applied): scientific and clinical instantiations under real-world constraints - **Cross-cutting** (theory/safety/eval): conceptual vocabulary, safety constraints, evaluation infrastructure **Unifying meta-principle:** the "information gap as training signal" pattern — skill libraries exploit skill-augmented vs. skill-free performance, memory evolution exploits memory-rich vs. memory-poor contexts, policy evolution exploits successful vs. failed trajectories.Source content preview — memskill.md
```yaml type: source id: memskill milestone: "[[memory-evolution]]" tags: [memory-evolution, year/2026, venue/arXiv] ``` > **one_line:** "MemSkill reframes agent memory extraction from fixed hand-designed operations into a learnable, evolvable skill bank" **Novel Insight:** - *prior:* Memory management = content problem, solved with fixed logic (add/update/delete) - *update:* The extraction procedure is itself a variable — separating "how to remember" from "what to remember" enables joint optimization **Temporal Relations:** - `extends` [[cascade]] — same learning principle, different target layer - `complements` [[skillrl]] — orthogonal skill domains, shared optimization pattern - `contrasts_with` [[yunjue-agent]] — executable code vs. declarative skills💎 The Karpathy Pattern
“Using LLMs to build personal knowledge bases… a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge.” — Andrej Karpathy
| Karpathy’s Vision | AutoWiki |
|---|---|
| “Index source documents into directory” | raw/ with extracted assets |
| “LLM incrementally compiles a wiki” | kb/ — analysis, synthesis, temporal positioning |
| “Backlinks, categorizes, writes articles” | [[wikilinks]] + milestone hierarchy |
| “Obsidian as the IDE frontend” | Project root = Obsidian vault |
| “LLM writes and maintains all the data” | Agent owns kb/ — proactive write-back |
| “LLM health checks over the wiki” | 25+ lint checks |
Why This Architecture?
Why Markdown? LLMs work natively with text. No ORM, no migrations. Obsidian renders it beautifully — graph view, backlinks, all for free.
Why not RAG? At personal KB scale (~100s of sources), a well-maintained index + grep outperforms vector search. No embedding pipeline needed.
Why a skill? SKILL.md IS the architecture — 390 lines encoding quality standards, anti-patterns, and workflow rules. No servers, no infra.
📄 License
MIT — see LICENSE.